
Intro
I would like to start a miniseries of blogs where I try to summarize lessons learned from large data loading into clustered column store index tables (CCI). In this blog I will describe an issue that would come as no surprise to most SQL experienced people but can hit anyone and have a big impact for CCI bulk load.
Scenario with CCI
We use clustered column store index tables (CCI) as main storage in a database for fact data. There are several reasons to do this. The main one for us was the size of the final table as we store billions of rows in there. In our case, as this is a highly denormalized fact table, with compression factor over 60. We do not perform any analytical queries on the top of those tables as it primarily serves as data source for SSAS. However, we need to perform some enhancing and aggregation steps with the data, so we transform data through different stages.
To be efficient with CCI we want our ETL SQL statements to be
- Parallel
- Bulk insert – to get COMPRESSED state of the segment directly. And have minimally logged Insert. (As it’s DWH we use simple recovery mode)
- Run in Batches – We added batching concept as some aggregation and join queries cannot be done on top of tables of this size. Those batches are done by dynamic sql statements driven by metadata.
- Use segment elimination to be efficient in all subsequent stages. We organize CCI to use segment elimination in batches.
So far, we have not come to the conclusion that we would need partitions.
Issue
But let’s go back to the main topic. We handle in our ETL framework consistency of the data in different steps by ourselves. Therefore, we have ID of the process which loaded data in each row, so we can identify the scope of the transformation into the next stage.
Process example:
-
Load data into Stage (STG)
- Create ETLProcessID 1 in ETLProcess Table with Status Running
- Load Data into fact and set ETLProcessID to 1 in stage.
- Update ETLProcess table Status to Success for ETLProcessID 1.
-
When loading data to Datamart layer (DM) we perform the following steps.
- Check stage which ETL processes are there with Success state. And store the list into work table.
- Perform data transfer for Facts with condition to take only ETLProcessIDs in the list.
For a better explanation this would be the state of the tables in DM Loading phase:
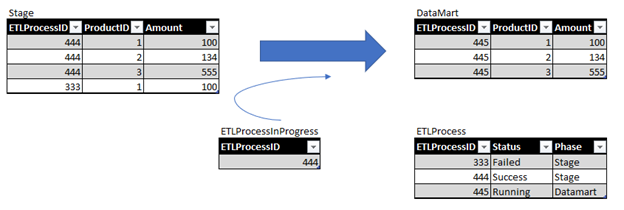
In the point 2.b there is unexpected trap. As ETLProcessID is ever increasing it might happen in some time with data manipulation in this work table statistic will not cover newly inserted ETL ID. And therefore, estimate will expect low number of rows. Example of the query and execution plan we have used is in the following screen-shot.
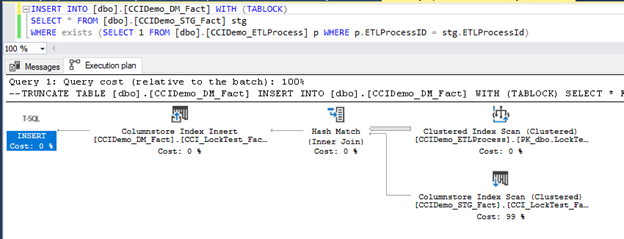
This plan is wrong for various reasons:
- Query optimizer estimated 1 row (based on statistics and histogram aligning algorithm) as a result of JOIN.
- Based on the reason above it switches Parallel execution to single thread and avoids bulk insert into target table.
If you get query execution plan like this for multimillion table, you will end up with:
- Trickle insert – Single threaded, fully logged insert operation.
- Because of Trickle Insert
– we have CLOSED segments instead of COMPRESSED segments. Tuple mover will then later compress those segments.
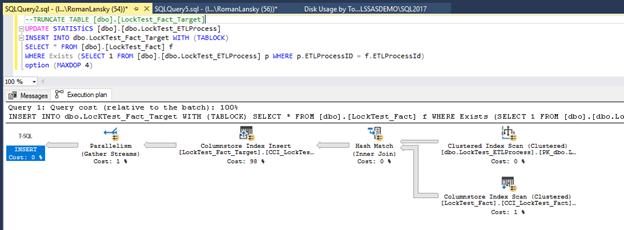
In this case it’s enough to update statistics on ETLProcess table (small one so it’s fast) before you run data load on facts. In that case we get the plan, performance and behavior we want.
- Parallel execution
- Bulk insert directly onto COMPRESSED Segments.
Lesson Learned
- Even small table statistics can be crucial for your “big query”.
- TABLOCK hint neither guarantee parallel execution and bulk load nor minimal logging.


