
Introduction
In my last blog post, I have addressed an issue with DAX Median function consuming a lot of memory. To refresh the result, below is the performance summary of those implementations. More on that topic you can find in this previous article.
| Performance for hour attribute (24 values) |
Duration (s) | Memory Consumed (GB) |
| Native median function |
71.00 |
8.00 |
| Custom implementation 1 |
6.30 |
0.20 |
| Many2Many median implementation |
2.20 |
0.02 |
| Performance for location attribute (422 values) |
Duration (s) | Memory Consumed (GB) |
| Native median function |
81.00 |
8.00 |
| Custom implementation 1 |
107.00 |
2.50 |
| Many2Many median implementation |
41.10 |
0.08 |
It seems we have solved the issue with memory but still, the duration of this query when used with locations is not user-friendly.
Today we will focus on the performance part.
Tuning 3 – Improve User Experience
I did not find how to improve the performance with some significant change of DAX or model. As such, I was thinking if we can somehow use aggregations for the median.
| MEASURE Senzors[Calc_MedTempMap] = VAR _mep = [MedianPositionEven] VAR _mepOdd = [MedianPositionOdd] VAR _TempMedianTable = ADDCOLUMNS( values ( TemperatureMapping[temperature]), „MMIN“, [RowCount]– [TemperatureMappingRowCount] +1 , „MMAX“, [RowCount]) VAR _T_MedianVals = FILTER ( _TempMedianTable , ( _mep >= [MMIN] && _mep <= [MMAX] ) || ( _mepOdd >= [MMIN] && _mepOdd <= [MMAX] )) RETURN AVERAGEX ( _T_MedianVals, [temperature] ) |
The part highlighted is still the critical one having the biggest impact on performance because formula engine needs to do the following:
– Iterate through all values we have on visual (for example location)
– For each item take a list of temperatures
– For each temperature get a cumulative count (sum of all counts of lower temperatures)
Although we made faster a less expensive cumulative count, we are doing too many loops in the formula engine evaluating similar values again and again.
What about to pre-calculate „_TempMedianTable“ table so we don’t have to change the algorithm but just pick up cumulative counts as a materialized column?
This is how the new model would look like:
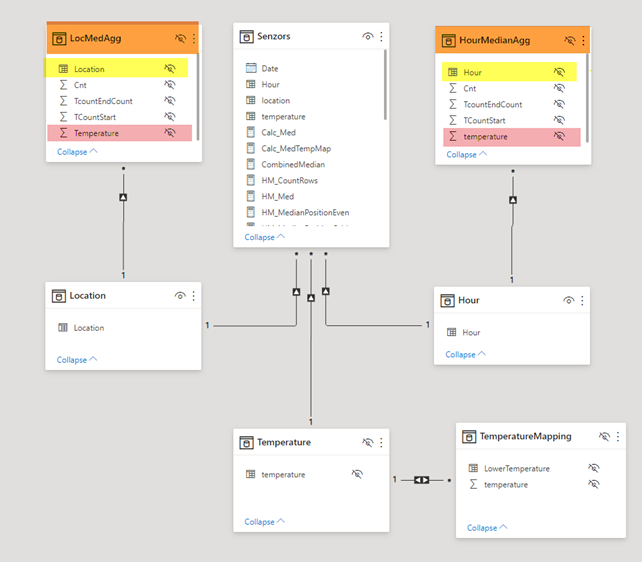
We can do the aggregation in the source system or we can do it even in Power BI, because we have less memory consumption.
There are two helper tables:
- LocMedAgg – for analyses through a location.
- HourMedianAgg – for analyses by hour.
Now we need to create an hour and location-specific measures and then one combined measure which will switch among them according to the current selection of attributes made by the user.
This is DAX expression for LocMedAgg table:
| MEASURE Senzors[LocMedAgg] = FILTER ( SUMMARIZECOLUMNS ( Senzors[location], TemperatureMapping[temperature], „TcountEndCount“, [RowCount], „TCountStart“, [RowCount] – [TemperatureMappingRowCount] + 1, „Cnt“, [TemperatureMappingRowCount] ), — due to m2n relation we would have empty members we do not need and therefore let’s filter them NOT ( ISBLANK ( [TemperatureMappingRowCount] ) ) ) |
New definition for hour Median measure is:
| —————————————————————— MEASURE Senzors[HM_MedianPositionEven] = ROUNDUP ( ( [HM_CountRows] / 2 ), 0 ) —————————————————————— MEASURE —————————————————————— MEASURE |
However, when we bring it into the visualization, we see the following issue:
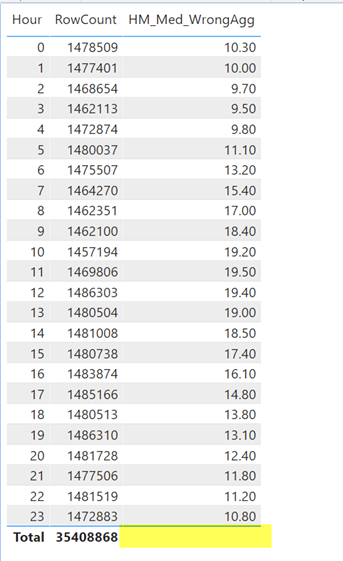
We are missing the total value. But that actually is no issue for us as we need to bring a context into the final calculation anyway, so we will compute the total value in a different branch of the final switch.
We create the aggregated median measures for location the same way as for hour, and then we put it all together in the final median calculation that switches among different median helpers.
For simplification, I wrapped the logic for each branch into a new measure, so the final calculation is simple:
| MEASURE Senzors[CombinedMedian] = SWITCH ( 1 = 1, [UseHourMedian], [HM_Med_NoAgg], [UseLocationMedian], [LM_Med_NoAgg], [IsDateFiltered], [Orig_Med], [Calc_MedTempMap] ) |
The switch above do this:
- If an hour and nothing else is selected use hour aggregation median calculation
- If location and nothing else is selected use location aggregation median
- If date attribute is selected use native median
- In all other cases use M2M median calculation
Below is one of the switching measures:
| MEASURE Senzors[IsDateFiltered] = — as I let engine to generate hierarchy for me I need to have this filter a bit complex to identify if any level of data is filtered ISFILTERED ( Senzors[Date].[Date] ) || ISFILTERED ( Senzors[Date].[Day] ) || ISFILTERED ( Senzors[Date].[Month] ) || ISFILTERED ( Senzors[Date].[MonthNo] ) || ISFILTERED ( Senzors[Date].[Quarter] ) || ISFILTERED ( Senzors[Date].[QuarterNo] ) || ISFILTERED ( Senzors[Date].[Year] ) MEASURE Senzors[UseHourMedian] = ISFILTERED ( ‚Hour'[Hour] ) && NOT ( ISFILTERED ( Location[Location] ) ) && |
And that’s it! Now we have solution where you get median under one second for major dimensions. You can download sample pbx from here.


