

Introduction
Fabric Warehouse is a new interesting tool used for data management and analysis. While it offers a wide range of features and functionalities, it is essential to be aware of its limitations to avoid any unexpected surprises during implementation. In this blog post, we will discuss three noteworthy limitations I encountered while working with Fabric Warehouse.
Feature 1
Absence of “IDENTITY” functionality and PRIMARY KEY Constraint:
In the screenshot below, you can see that Fabric Warehouse currently does not support the “IDENTITY” function, a feature I personally find extremely valuable. Additionally, the absence of the PRIMARY KEY constraint restricts the use of this essential database design element.
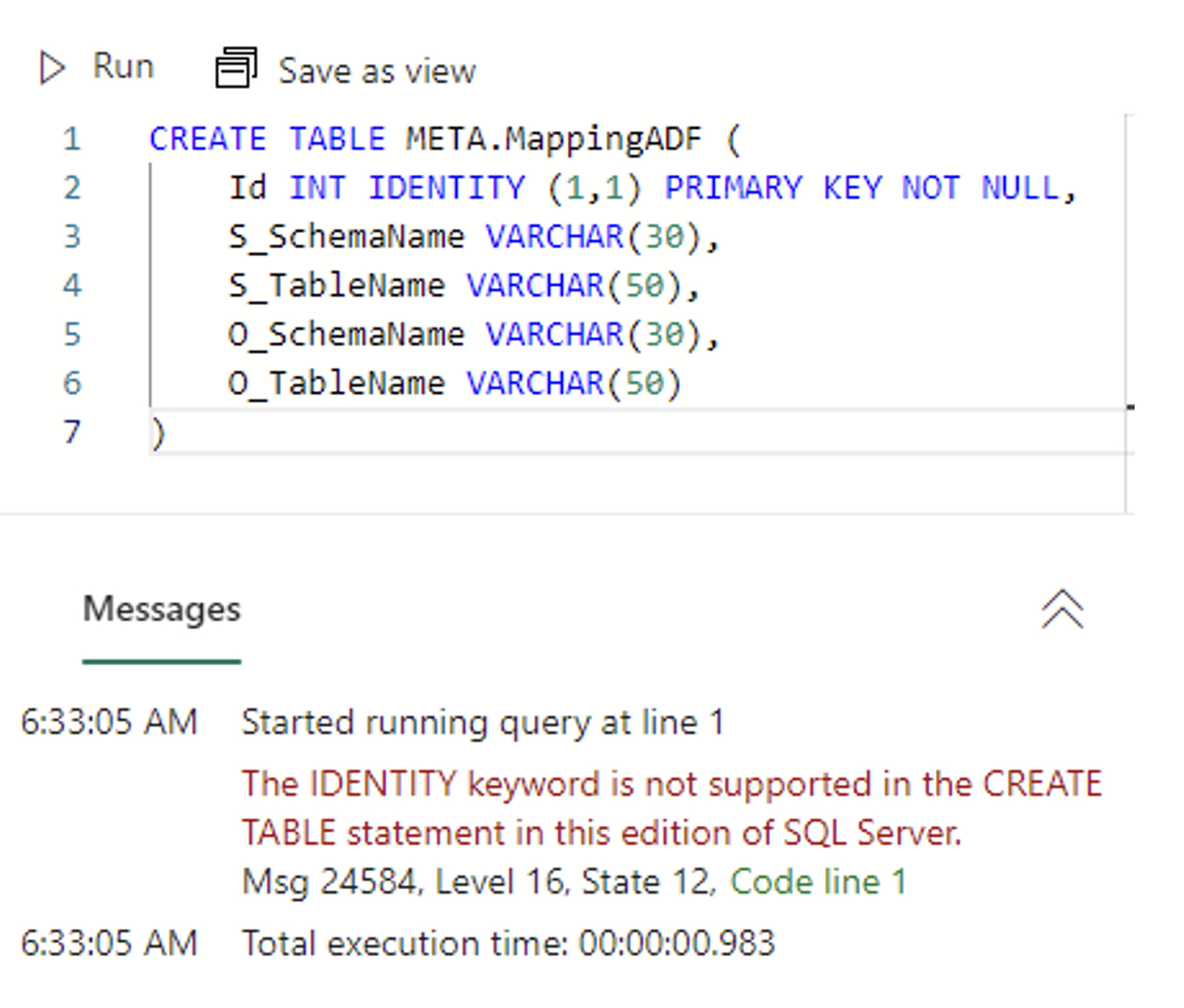
Picture 1 – Identity not supported
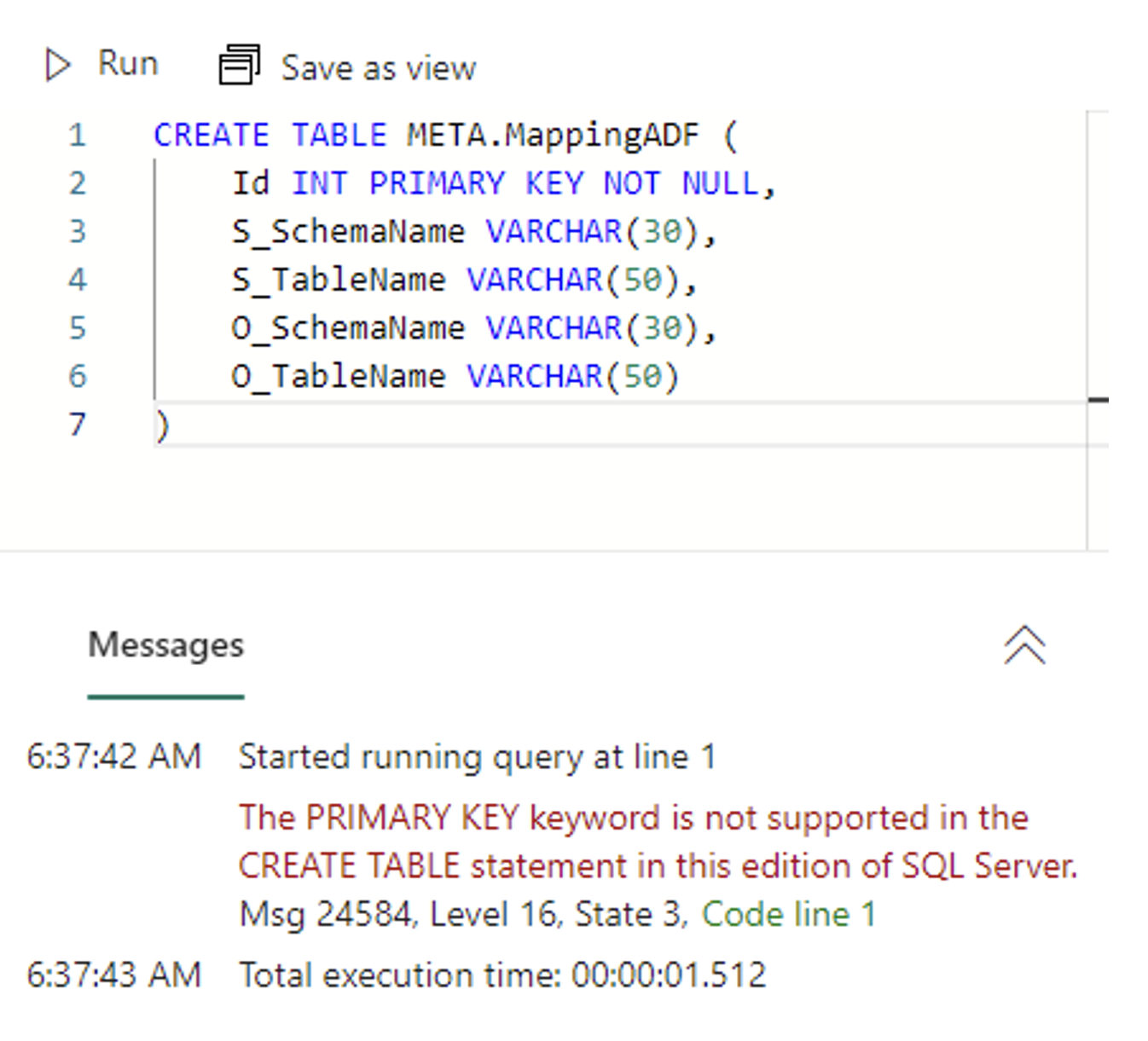
Picture 2 – Primary key not supported
However, if you still wish to incorporate automatic ID generation, you can try the following workaround:
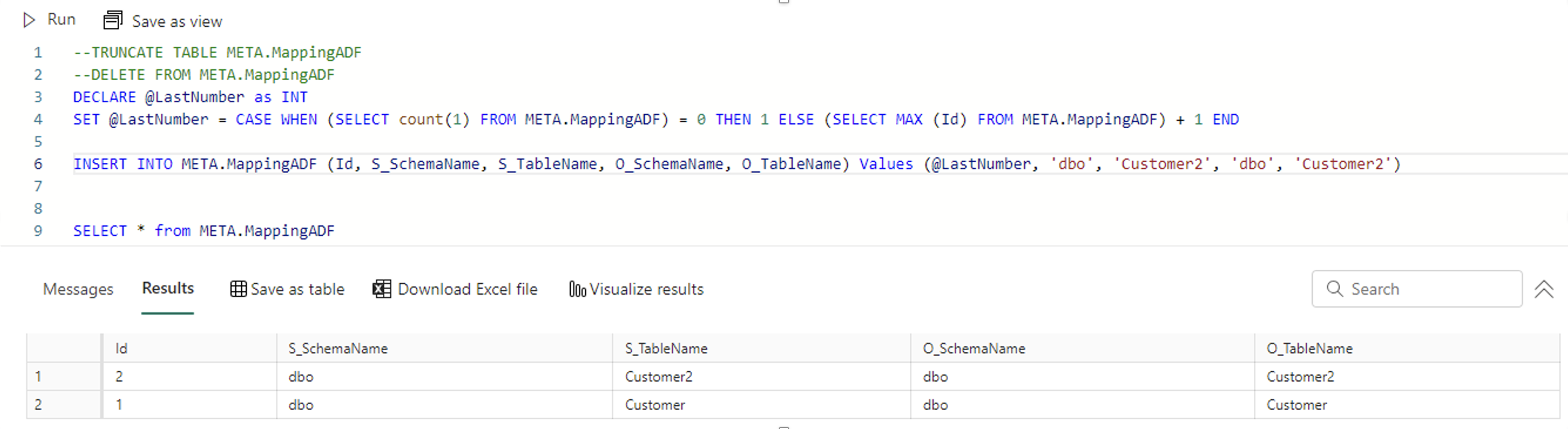
Picture 3 – Identity workaround
As a workaround, you can also utilize the row_number function. This function assigns a unique number to each row in a result set, allowing you to simulate the “IDENTITY” functionality and generate automatic IDs manually. By incorporating the row_number function into your queries, you can achieve a similar outcome to the missing “IDENTITY” functionality in Fabric Warehouse. While this workaround requires additional manual effort, it can be an effective solution until the “IDENTITY” feature is introduced in future updates of Fabric Warehouse.
Feature 2
Lack of Truncate Table Support:
Another surprising discovery I made while working with Fabric Warehouse is the absence of support for the “Truncate Table” statement. This statement is commonly used to remove all rows from a table efficiently.

Picture 4 – Truncate table not supported
In the absence of this feature, you will need to rely on the DELETE statement for removing records from a table. Although DELETE achieves the same outcome, it might be less performant for larger datasets. Ensure you consider the potential impact on performance when working with Fabric Warehouse.
Another workaround could be DROP TABLE / CREATE TABLE.
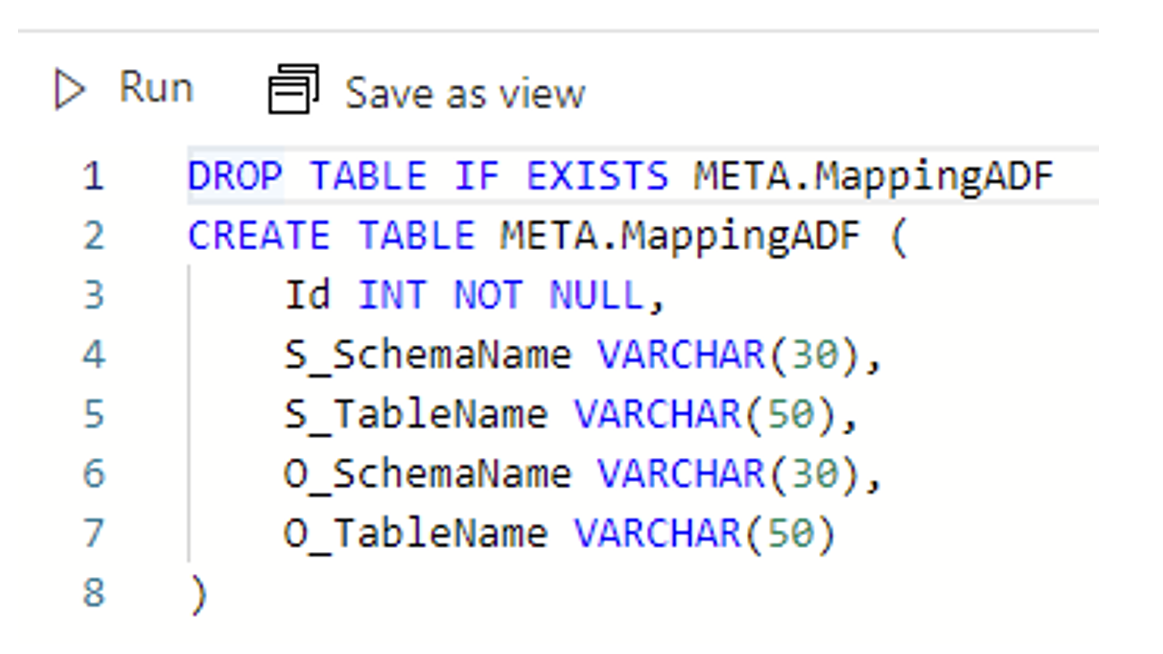
Picture 5 – Drop Table If Exists
Feature 3
Non-support for NVARCHAR Data Type:
One of the most unexpected limitations I encountered in Fabric Warehouse was the absence of support for my favorite data type, NVARCHAR.

Picture 6 – The list of supported data types.
The current list of data types can be found in the official Microsoft documentation.
https://learn.microsoft.com/en-us/fabric/data-warehouse/data-types
Conclusion
Fabric Warehouse, being in the public preview stage, is a dynamic tool that is continuously evolving. While it may have certain limitations at present, it is important to note that Microsoft Fabric regularly releases updates to enhance its functionality. Similar to the monthly updates we’ve seen with Power BI, it is possible that Fabric Warehouse will incorporate the missing features discussed in this blog post in the near future.
By keeping an eye on the updates and roadmaps provided by Microsoft, you can stay informed about the latest advancements and feature additions to Fabric Warehouse.
In the meantime, it is recommended to work within the current capabilities of Fabric Warehouse and explore alternative approaches or workarounds to achieve your desired outcomes.

I have been dealing with MS SQL Server for several years. I enjoy both scripting and server administration. Joyful Craftsmen allowed me to deepen my knowledge on cloud solutions as well. Therefore, I would like to share with you the acquired knowledge in the field of data migration to Azure. I’m interested in Power BI and Microsoft Fabric as well.



1 Comment. Leave new
The lack of IDENTITY and PK is kinda by design. It’s considered an anti-pattern to use these “features” in an MPP-style database. Reason being: to get good parallelism you have to assume that each processing node will run independently of the others. This is nothing new and is a limitation of every MPP I am aware of. The correct design pattern is to either use a pre-processing stage of the ETL for key assignment or a post-processing phase to eliminate rows that don’t match a constraint. This is especially true for FKs which are also not supported in MPPs.
The lack of nvarchar is definitely obnoxious.