


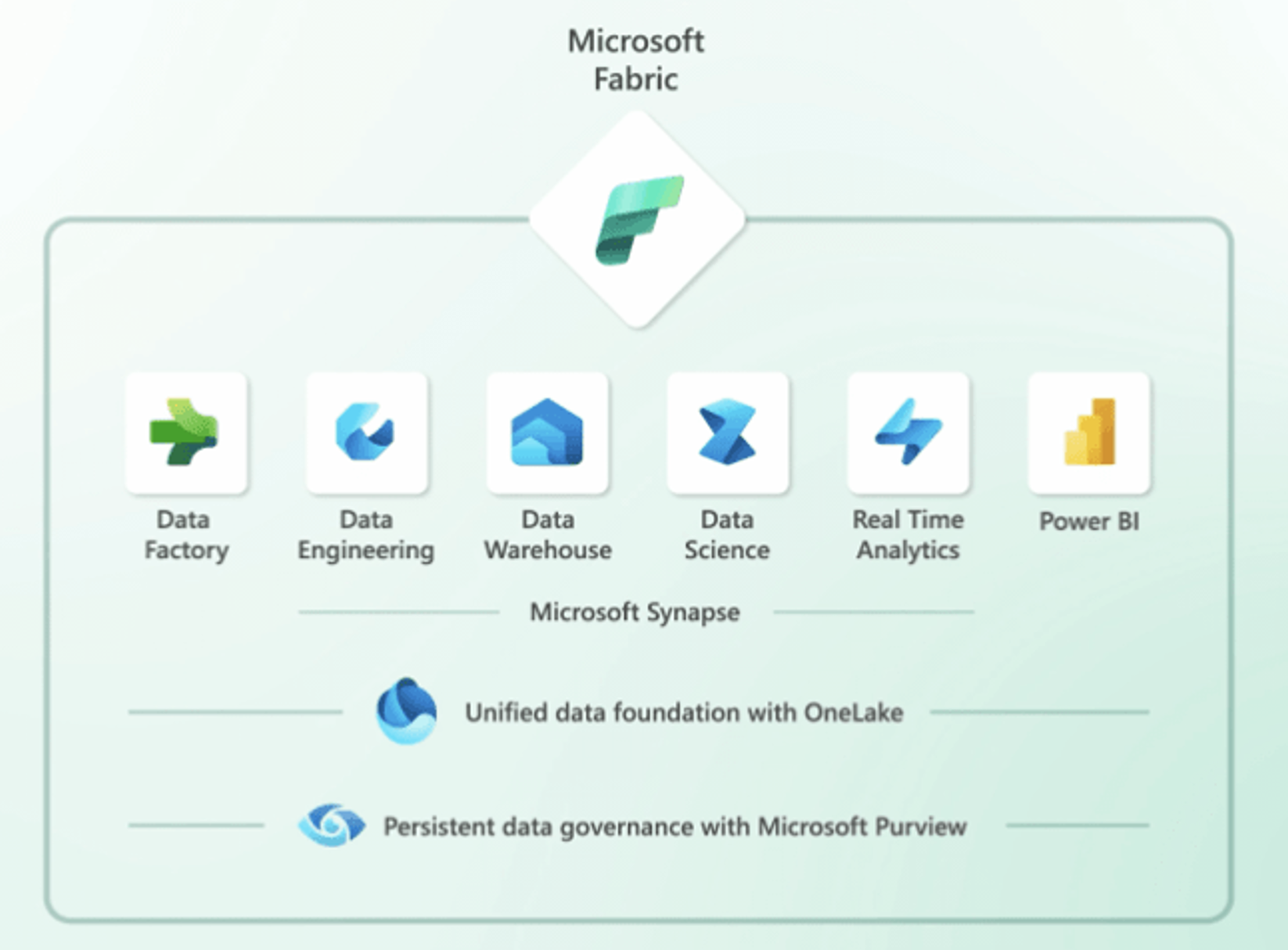
The buzz around Microsoft Fabric has been growing steadily since its announcement. This game-changing platform unifies several critical Azure services, including Data Factory, Synapse, and Power BI, all under one cohesive interface. One of its most significant features is its emphasis on the Lakehouse Platform, storing all data in the Delta Format. This centralizes data and reports in the „OneLake,“ a repository similar to OneDrive for Data.
Fabric simplifies development and collaboration by saving everything within dedicated workspaces. However, if your organization is already invested in Azure Synapse and has ongoing projects using other Azure resources, you might be wondering how to navigate this transition effectively. In this blog post, we’ll explore some key design ideas for a smooth transition to Microsoft Fabric, without the need to pause, redesign, rebuild, or start from scratch.
Why Not Rush into the New and Shiny?
Before diving into the technical capabilities you can align in your existing data architecture, it’s essential to address the question of why you shouldn’t rush to embrace the new and shiny. In the ever-evolving world of cloud technology, it’s easy to get caught up in the excitement of the latest innovations. However, a pragmatic approach is often more advisable.
Here’s why:
- Stability: Existing systems and technologies are usually more stable and mature, making them reliable choices for ongoing projects.
- Cost-Efficiency: Transitioning to a new platform can be costly in terms of time, resources, and potential disruptions. Leveraging what you already have can save money.
- Minimized Disruption: Avoiding major overhauls means less disruption to ongoing projects, reducing the risk of downtime and delays.
- Incremental Innovation: You can still take advantage of the latest innovations as they become relevant to your organization without starting from scratch.
Key Technical Considerations for a Smooth Transition:
Now, let’s delve into the technical capabilities you can align within your existing data architecture to facilitate a seamless move to Microsoft Fabric when the time is right:
Delta Lake Compatibility: If your existing Data Lake uses the Delta Lake open-source standard for formatting datasets, you’re well-positioned to migrate to Microsoft Fabric when the opportunity arises. Delta Lake’s support for structured and unstructured data makes data migration smoother. By adopting Delta Format, organizations can store their data in a manner that aligns seamlessly with Fabric’s architecture.
Apache Spark Compute: If you’re using Spark compute, whether in Databricks or Synapse, any Python or Scala notebooks you’ve written can be adapted for use in Microsoft Fabric with minimal adjustments. To interact most efficiently and flexibly with the Delta Format, Apache Spark emerges as a key player. Apache Spark, known for its versatility, provides interfaces with SQL, Python, Scala, and R. While SQL functions within Spark are valuable, they truly shine when coupled with a flexible and user-friendly programming language like Python.

Serverless SQL Pools: If you’ve been using Serverless SQL Pools in Synapse Analytics to model data, those table definitions can be carried over to Microsoft Fabric Data Warehouse. This ensures continuity in your data modeling efforts.
Data Factory Pipelines: Data Factory pipelines, commonly used for data orchestration, can be seamlessly moved or mounted within Microsoft Fabric. This means you don’t have to recreate your data workflows from scratch.
Data Explorer and Kusto Queries: If you’ve been using Data Explorer and Kusto queries, you can migrate these to the Microsoft Fabric Realtime Analytics experience, ensuring a smooth transition for real-time data processing needs.
Skillset Implications:
However, it’s essential to acknowledge that transitioning to Fabric, especially when embracing Apache Spark, may require some adjustments to your data team’s skillset. Your existing data warehouse team might excel in SQL but may need additional training in languages like Python to fully leverage Spark’s capabilities.
The good news is that if your team is already accustomed to using Azure Synapse Analytics with Spark or Dataflows, the migration should be relatively straightforward. The familiarity with Spark will serve as a solid foundation for adapting to Fabric’s ecosystem.
Conclusion:
In conclusion, transitioning from Azure Synapse to Microsoft Fabric doesn’t have to be a daunting task. By taking a pragmatic approach and leveraging your existing technical capabilities, you can evolve your data architecture at your own pace. This allows you to embrace the benefits of Microsoft Fabric when it makes sense for your organization, without the need to pause or overhaul ongoing projects.
Remember, it’s not about rushing into the new and shiny; it’s about making informed, strategic decisions for your data architecture’s future. By incorporating Delta Format and Apache Spark into your existing infrastructure, you ensure a smooth transition to Microsoft Fabric, positioning your organization for future success in the evolving landscape of data analytics.

Data Engineer at Joyful Craftsmen, experienced in on-premise data warehouses and MS SQL. Passionate about modern data warehouse technology, leveraging Azure Cloud’s capabilities. Particularly enthusiastic about utilizing Databricks for effective data processing. Let’s collaborate to turn data into actionable insights!


